
-
chevron_right
Erlang Solutions: What businesses should consider when adopting AI and machine learning
news.movim.eu / PlanetJabber · Thursday, 31 August, 2023 - 09:29 · 5 minutes
AI is everywhere. The chatter about chatbots has crossed from the technology press to the front pages of national newspapers. Worried workers in a wide range of industries are asking if AI will take their jobs.
Away from the headlines, organisations of all sizes are getting on with the task of working out what AI can do for them. It will almost certainly do something. One survey puts AI’s potential boost to the global economy at an eye watering US$15.7tr by 2030 .
Those major gains will come from productivity enhancements, better data-driven decision making and enhanced product development, among other AI benefits.
It’s clear from all this that most businesses can’t afford to ignore the AI revolution. It has the very real potential to cut costs and create better customer experiences.
Quite simply, it can make businesses better. If you’re not at least thinking about AI right now, you should be aware that your competitors probably are.
So the question is, what AI tools and processes are the right ones for you, and how do you implement groundbreaking technology that actually works, without disrupting day-to-day workflows? Here are a few things to consider.
AI or machine learning?
The first thing is to be clear about what you mean by AI.

AI is an umbrella term for technologies that attempt to mimic human intelligence. Perhaps the most important, at least at the moment, is machine learning (ML).
ML tools analyse existing data to create business-enhancing insight. The more data they’re exposed to, the more they ‘learn’ what to look out for. They find patterns and trends in mountains of information and do so at speed.
As far as business is concerned, those patterns might pinpoint unusual sales trends, potential production bottlenecks, or hidden productivity issues. They might reveal a hundred other potential opportunities and challenges. The important thing to remember is that ML of this kind automates the ability to learn from what has gone before.
ChatGPT and similar technologies, meanwhile, are part of a class of tools called generative AI. These applications also use machine learning techniques to mine huge datasets but do so for fundamentally different reasons.
If ML looks back at existing materials, generative AI looks forward and creates new ones. One obvious role is in creating content, but generative tools can also produce code, business simulations and product designs.
These two AI technologies can work together. For example, they might be tasked with automating the production of reports based on detailed analysis of a previous year’s data.
Work out your goals for AI and machine learning
Once you know a little about different AI tools, the next step is to understand what they can do for you. Begin with a business goal, not a technology.
Start by identifying problems you need to solve, or opportunities you want to grasp. Maybe you want to create data-driven marketing campaigns for different customer segments. Maybe your website is crying out for a series of basic ‘how-to’ animations. Maybe you have processes that are ripe for automation?
Whatever it is, the key is to identify the challenges you face and the opportunities you can take advantage of, and then mould an AI strategy that meets real business goals.
Become a data-centric organisation
As we’ve seen, AI and ML are dependent on data, and lots of it. The more data they can use, the more accurate and useful they tend to be.
But data can be problematic. It is diverse, fragmented and often unstructured. It needs to be stored and moved securely and in line with relevant privacy regulations. All of this means that to make it valuable, you need to create a data management strategy.
That strategy needs to address challenges related to data sourcing, storage, quality, governance, integration, analysis and culture.
Corporate data is typically spread across an organisation and often found squirrelled away in the silos of legacy technology systems. It needs to be pooled, formatted and made accessible to the AI and ML tools of different departments and business units. Data is only useful when it’s available.
AI and machine learning: Start small and keep it simple
All of this makes implementing AI and ML sound like a highly time-consuming and complex undertaking. But it needn’t be, and especially not at first.
The secret to most successful technology implementations is to start small and simple. That’s doubly true with something as potentially game-changing as AI and ML.
For example, start applying ML tools to just a small section of your data, rather than trying to do too much too soon. Pick a specific challenge that you have, focus on it, and experiment with refining processes to achieve better results. Then increase AI use incrementally as the technology proves its worth.
Bring your team with you
Much of the recent publicity around AI has focused on doom-laden predictions of mass unemployment. When you talk about adopting AI and ML in your organisation, employee alarm bells may start ringing, which could have serious implications for staff morale and productivity.
But in most organisations, AI is about augmenting human effort, not replacing it. AI and ML can automate the mundane tasks people don’t like doing, freeing them up for more creative activity. It can provide insight that improves human decision making, but humans still make the decisions. It is far from perfect, and human oversight of AI is required at every step.
Your communications around the implementation of AI should emphasise these points. AI is a tool for your people to use, not a substitute for their efforts.
Elixir and Erlang machine learning
As businesses become familiar with AI and ML tools, they may start creating their own, tailored to their specific needs and circumstances. Organisations that develop and modify AI and ML tools increasingly do so using Elixir, a programming language based on the Erlang Virtual Machine (VM).
Elixir is perfect for creating scalable AI applications for three core reasons:
- Concurrency: Elixir is designed to handle lots of tasks simultaneously, which is ideal for AI applications that have to process large amounts of data from different sources.
- Functional programming: Elixir focuses on function – reaching a desired goal as simply as possible. That’s perfect for AI because the simpler your AI algorithms, the more reliable they are likely to be.
- Distributed computing: AI applications demand significant computational resources that developers spread across multiple machines. Elixir offers in-built distribution capabilities, making distributed computing straightforward.
In addition, Elixir is supported by a wide range of libraries and tools, providing ready-made solutions to challenges and shortening the development journey.
The result is AI applications that are efficient, scalable and reliable. That’s hugely important because as AI and ML become ever more crucial to business success, effective applications and processes will become a fundamental business differentiator. AI isn’t something you can ignore. If you aren’t already, start thinking about your own AI and ML strategy today.
Want to know more about efficient, effective AI development with Elixir? Talk to us .
The post What businesses should consider when adopting AI and machine learning appeared first on Erlang Solutions .









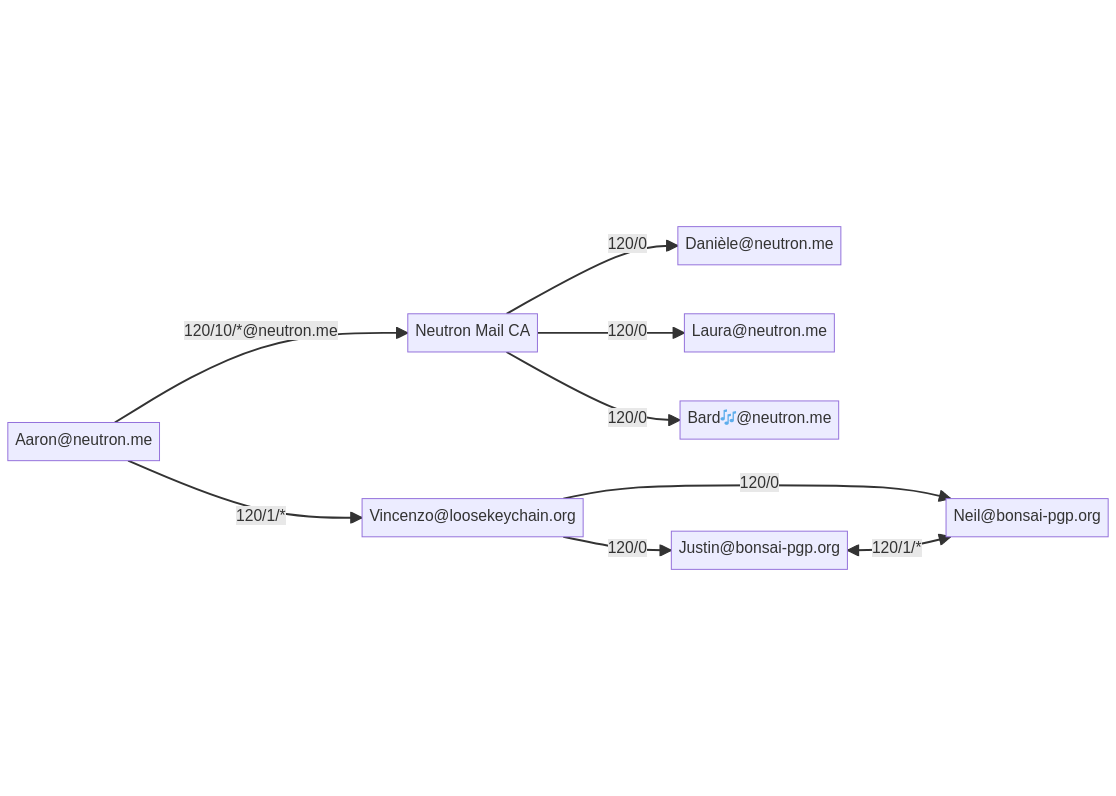 An example for an OpenPGP Web-of-Trust. Simply by delegating trust to the Neutron Mail CA and to Vincenzo, Aaron is able to authenticate a number of certificates.
An example for an OpenPGP Web-of-Trust. Simply by delegating trust to the Neutron Mail CA and to Vincenzo, Aaron is able to authenticate a number of certificates.