-
Pl
chevron_right
Andy Wingo: the value of a performance oracle
news.movim.eu / PlanetGnome • 7 April 2026 • 5 minutes
Over on his excellent blog, Matt Keeter posts some results from having ported a bytecode virtual machine to tail-calling style . He finds that his tail-calling interpreter written in Rust beats his switch-based interpreter, and even beats hand-coded assembly on some platforms.
He also compares tail-calling versus switch-based interpreters on WebAssembly, and concludes that performance of tail-calling interpreters in Wasm is terrible:
1.2× slower on Firefox, 3.7× slower on Chrome, and 4.6× slower in wasmtime. I guess patterns which generate good assembly don't map well to the WASM stack machine, and the JITs aren't smart enough to lower it to optimal machine code.
In this article, I would like to argue the opposite: patterns that generate good assembly map just fine to the Wasm stack machine, and the underperformance of V8, SpiderMonkey, and Wasmtime is an accident.
some numbers
I re-ran Matt’s experiment locally on my x86-64 machine (AMD Ryzen Threadripper PRO 5955WX). I tested three toolchains:
-
Compiled natively via cargo / rustc
-
Compiled to WebAssembly, then run with Wasmtime
-
Compiled to WebAssembly, then run with Wastrel
For each of these toolchains, I tested Raven as implemented in Rust in both “switch-based” and “tail-calling” modes. Additionally, Matt has a Raven implementation written directly in assembly; I test this as well, for the native toolchain. All results use nightly/git toolchains from 7 April 2026.
My results confirm Matt’s for the native and wasmtime toolchains, but wastrel puts them in context:
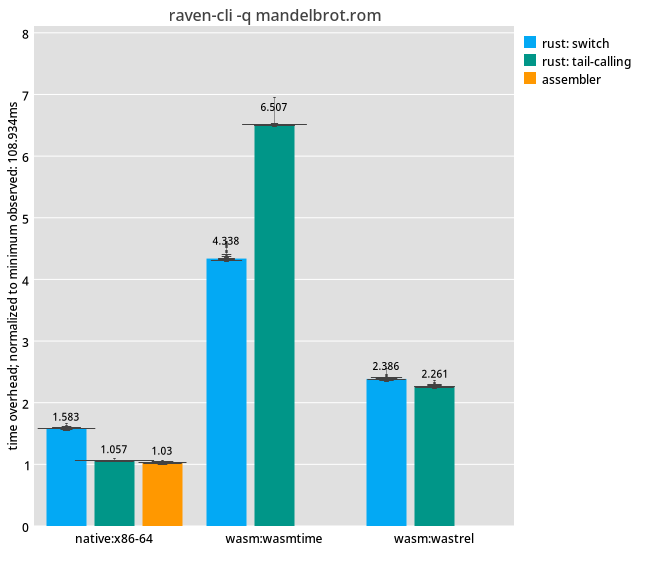
We can read this chart from left to right: a switch-based interpreter written in Rust is 1.5× slower than a tail-calling interpreter, and the tail-calling interpreter just about reaches the speed of hand-written assembler. (Testing on AArch64, Matt even sees the tail-calling interpreter beating his hand-written assembler.)
Then moving to WebAssembly run using Wasmtime, we see that Wasmtime takes 4.3× as much time to run the switch-based interpreter, compared to the fastest run from the hand-written assembler, and worse, actually shows 6.5× overhead for the tail-calling interpreter. Hence Matt’s conclusions: there must be something wrong with WebAssembly.
But if we compare to Wastrel , we see a different story: Wastrel runs the basic interpreter with 2.4× overhead, and the tail-calling interpreter improves on this marginally with a 2.3x overhead. Now, granted, two-point-whatever-x is not one; Matt’s Raven VM still runs slower in Wasm than when compiled natively. Still, a tail-calling interpreter is inherently a pretty good idea.
where does the time go
When I think about it, there’s no reason that the switch-based interpreter should be slower when compiled via Wastrel than when compiled via rustc . Memory accesses via Wasm should actually be cheaper due to 32-bit pointers, and all the rest of it should be pretty much the same. I looked at the assembly that Wastrel produces and I see most of the patterns that I would expect.
I do see, however, that Wastrel repeatedly reloads a struct memory value, containing the address (and size) of main memory. I need to figure out a way to keep this value in registers. I don’t know what’s up with the other Wasm implementations here; for Wastrel, I get 98% of time spent in the single interpreter function, and surely this is bread-and-butter for an optimizing compiler such as Cranelift. I tried pre-compilation in Wasmtime but it didn’t help. It could be that there is a different Wasmtime configuration that allows for higher performance.
Things are more nuanced for the tail-calling VM. When compiling natively, Matt is careful to use a preserve_none calling convention for the opcode-implementing functions, which allows LLVM to allocate more registers to function parameters; this is just as well, as it seems that his opcodes have around 9 parameters. Wastrel currently uses GCC’s default calling convention, which only has 6 registers for non-floating-point arguments on x86-64, leaving three values to be passed via global variables (described here ); this obviously will be slower than the native build. Perhaps Wastrel should add the equivalent annotation to tail-calling functions.
On the one hand, Cranelift (and V8) are a bit more constrained than Wastrel by their function-at-a-time compilation model that privileges latency over throughput; and as they allow Wasm modules to be instantiated at run-time, functions are effectively closures, in which the “instance” is an additional hidden dynamic parameter. On the other hand, these compilers get to choose an ABI; last I looked into it, SpiderMonkey used the equivalent of preserve_none , which would allow it to allocate more registers to function parameters. But it doesn’t: you only get 6 register arguments on x86-64, and only 8 on AArch64. Something to fix, perhaps, in the Wasm engines, but also something to keep in mind when making tail-calling virtual machines: there are only so many registers available for VM state.
the value of time
Well friends, you know us compiler types: we walk a line between collegial and catty. In that regard, I won’t deny that I was delighted when I saw the Wastrel numbers coming in better than Wasmtime! Of course, most of the credit goes to GCC; Wastrel is a relatively small wrapper on top.
But my message is not about the relative worth of different Wasm implementations. Rather, it is that performance oracles are a public good : a fast implementation of a particular algorithm is of use to everyone who uses that algorithm, whether they use that implementation or not.
This happens in two ways. Firstly, faster implementations advance the state of the art, and through competition-driven convergence will in time result in better performance for all implementations. Someone in Google will see these benchmarks, turn them into an OKR, and golf their way to a faster web and also hopefully a bonus.
Secondly, there is a dialectic between the state of the art and our collective imagination of what is possible, and advancing one will eventually ratchet the other forward. We can forgive the conclusion that “patterns which generate good assembly don’t map well to the WASM stack machine” as long as Wasm implementations fall short; but having showed that good performance is possible, our toolkit of applicable patterns in source languages also expands to new horizons.
Well, that is all for today. Until next time, happy hacking!