Introducing ejabberd 24.06: Deep Work Release!
Introducing ejabberd 24.06: Deep Work Release!
This new ejabberd 24.06 includes four months of work, close to 200 commits, including several minor improvements in the core ejabberd, and a lot of improvements in the administrative parts of ejabberd, like the WebAdmin and new API commands.

Brief summary
-
Webadmin rework
-
Improved documentation
-
Architecture and API improvements
If you upgrade ejabberd from a previous release, please review those changes:
A more detailed explanation of those topics and other features:
Support for Erlang/OTP 27 and Elixir 1.17
ejabberd support for Erlang/OTP 27.0 has been improved. In this sense, when using Erlang/OTP 27, the
jiffy
dependency is not needed, as an equivalent feature is already included in OTP.
The lowest supported Erlang/OTP version continues being 20.0, and the recommendation is using 26.3, which is in fact the one included in the binary installers and container images.
Regarding Elixir, the new 1.17 works correctly. The lowest Elixir supported version is 1.10.3… but in order to benefit from all the ejabberd features, it is highly recommended to use Elixir 1.13.4 or higher with Erlang/OTP 23.0 or higher.
SQL schema changes
There are no changes in the SQL schemas in this release.
Notice that ejabberd can take care to update your MySQL, PostgreSQL and SQLite database schema if you enable the
update_sql_schema
toplevel option.
That feature was introduced for beta-testing in
ejabberd 23.10
and announced in the blog post
Automatic schema update in ejabberd
.
Starting in this ejabberd 24.06, the
update_sql_schema
feature is considered stable and the option is enabled by default!
UNIX Socket Domain
The
sql_server
top-level option now accepts the path to a unix socket domain, expressed as
"unix:/path/to/socket"
, as long as you are using mysql or pgsql in the option
sql_type
.
Commands changed in API v2
This ejabberd 24.06 release introduces ejabberd Commands API v2. You can continue using API v1; or if you want to update your API client to use APIv2, those are the commands that changed and you may need to update in your client:
Support for banning an account has been improved in API v2:
–
ban_account
stores the ban information in the account XML private storage, so that command requires
mod_private
to be enabled
–
get_ban_details
shows information about the account banning, if any.
–
unban_account
performs the reverse operation, getting the account to its previous status.
The result value of those two commands was modified to allow their usage in WebAdmin:
–
kick_user
instead of returning an integer, it returns a restuple.
–
rooms_empty_destroy
instead of returning a list of rooms that were destroyed, it returns a
restuple
.
As a side note, this command has been improved, but this change doesn’t affect the API:
–
join_cluster
has been improved to work not only with the
ejabberdctl
command line script, but also with any other command frontend (
mod_http_api
,
ejabberd_xmlrpc
,
ejabberd_web_admin
, …).
New commands
Several new commands have been added, specially useful to generate WebAdmin pages:
Improved WebAdmin with commands usage
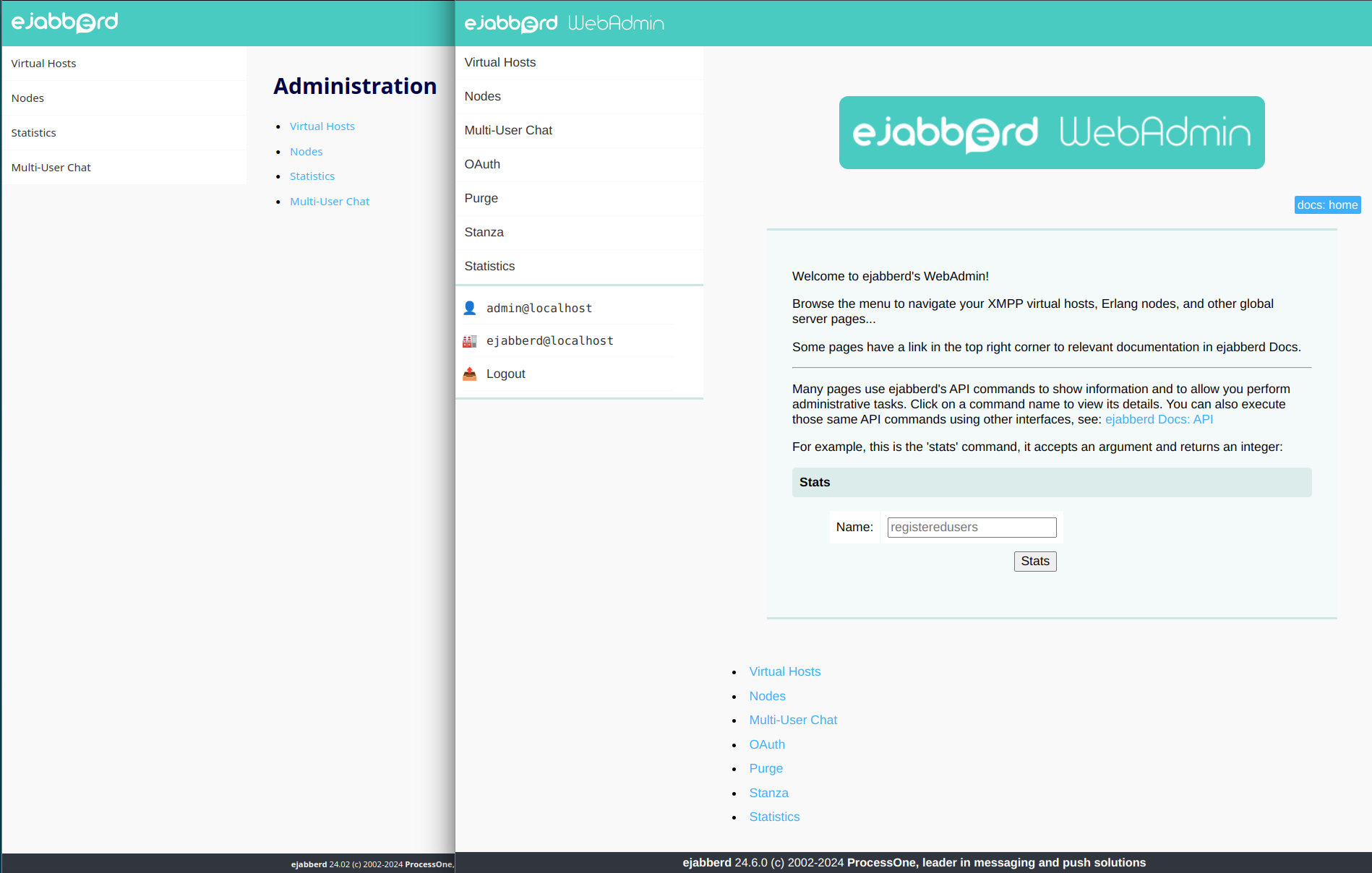
ejabberd already has around 200 commands to perform many administrative tasks, both to get information about the server and its status, and also to perform operations with side-effects. Those commands have its input and output parameters clearly described, and also documented.
This release includes a set of functions (
make_command/2
and
/4
,
make_command_raw_value/3
,
make_table/2
and
/4
) to use all those commands to generate HTML content in the ejabberd WebAdmin: instead of writing again erlang code to perform those operations and then write code to format it and display as HTML… let’s have some frontend functions to call the command and generate the HTML content. With that new feature, writing content for WebAdmin is much easier if a command for that task already exists.
In this sense, most of the ejabberd WebAdmin pages have been rewritten to use the new
make_command
feature, many new pages are added using the existing commands. Also a few commands and pages are added to manage Shared Roster Groups.
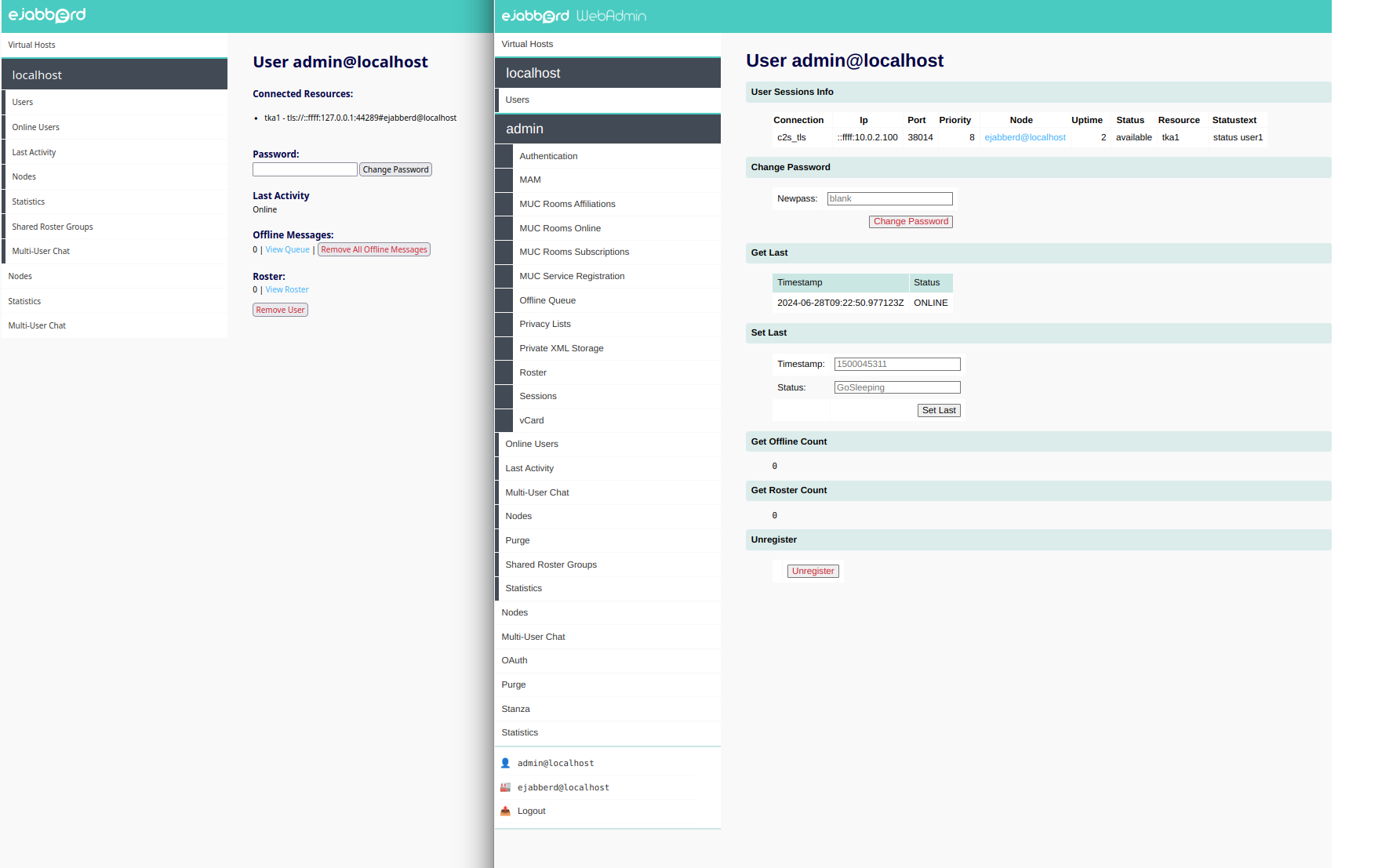
WebAdmin commands permissions configuration
Most WebAdmin pages use commands to generate the content, and access to those commands can be restricted using the
api_permissions
toplevel option
.
The default
ejabberd.yml
configuration file already defines
"admin access"
that allows access from loopback IP address and accounts in the
admin
ACL to execute all commands except
stop
and
start
. So, no changes are required in the default configuration file to use the upgrade WebAdmin pages.
Now
ejabberd_web_admin
is another valid command frontend that can be specified in the
from
section. You can define fine-grained restrictions for accounts in WebAdmin, for example:
api_permissions:
"webadmin commands":
from:
- ejabberd_web_admin
who: admin
what:
- "*"
- "![tag:oauth]"
WebAdmin hook changes
There are several changes in WebAdmin hooks that now provide the whole HTTP request instead of only some of its elements.
You can update your code easily, see:
-
webadmin_page_node
: instead of Path, Query and Lang, gets Request
-webadmin_page_node(Acc, Node, Path, Query, Lang) ->
+webadmin_page_node(Acc, Node, #request{path = Path, q = Query, lang = Lang}) ->
-
webadmin_page_hostnode
: instead of Path, Query and Lang gets Request
-webadmin_page_hostnode(Acc, Host, Node, Path, Query, Lang) ->
+webadmin_page_hostnode(Acc, Host, Node, #request{path = Path, q = Query, lang = Lang}) ->
-
webadmin_user
: instead of just the Lang, gets the whole Request
-webadmin_user(Acc, User, Server, Lang) ->
+webadmin_user(Acc, User, Server, #request{lang = Lang}) ->
-
webadmin_menu_hostuser
: new hook added:
+webadmin_menu_hostuser(Acc, Host, Username, Lang) ->
-
webadmin_page_hostuser
: new hook added:
+webadmin_page_hostuser(Acc, Host, Username, Request) ->
internal
command tag and
any
argument/result
During the development of the WebAdmin commands feature, it was noticed the necessity to define some commands that will be used by WebAdmin (or maybe also by other ejabberd code), but should NOT be accessed by command frontends (like
ejabberdctl
,
mod_http_api
,
ejabberd_xmlrpc
).
Such commands are identified because they have the
internal
tag.
Those commands can use any arbitrarily-formatted arguments/results, defined as
any
in the command.
Experimental
make format
and
indent
If you use Emacs with
erlang-mode
, Vim with some Erlang indenter, VSCode, … they indent erlang code more or less similarly, but sometimes have some minor differences.
The new
make format
uses https://github.com/AdRoll/rebar3_format to format and indent files, with those restrictions:
-
Only formats a file if it contains a line with this string, and formats only starting in that line:
%% @format-begin
-
Formatting can be disabled later in the file by adding another line that contains
%% @format-end
-
Furthermore, it is later possible to enable formatting again in the same file, in case there is another piece of the file that should be automatically formatted.
Alternatively, it is possible to indent files using Emacs, it also replaces tabs with blankspaces and removes ending spaces. The new
make indent
indents the lines between:
%% @indent-begin
...
%% @indent-end
New MUC room logging hooks
mod_muc_room
now uses hooks instead of function calls to
mod_muc_log
, see
#4191
.
The new hooks available, in case you want to write an ejabberd module that logs MUC room messages:
-
muc_log_check_access_log(Acc, Host, From)
-
muc_log_get_url(Acc, StateData)
-
muc_log_add(Host, Type, Data, RoomJid, Opts)
Support for code automatic update
When running ejabberd in an interactive development shell started using
relive
, it automatically compiles and reloads the source code when you modify a source code file.
How to use this:
-
Compile ejabberd with Rebar3 (or Mix)
-
Start ejabberd with
make relive
-
Edit some ejabberd source code file and save it
-
Sync
(or
ExSync
) will compile and reload it automatically
Rebar3 notes:
Mix note:
-
ExSync depends on FileSystem library, which requires inotify-tools, see https://github.com/falood/file_system#system-support
ejabberd Docs now using MkDocs
Several changes in ejabberd source code were done to produce markdown suitable for the new
ejabberd Docs
site, as announced two months ago:
ejabberd Docs now using MkDocs
Acknowledgments
We would like to thank the contributions to the source code, documentation, and translation provided for this release by:
And also to all the people contributing in the ejabberd chatroom, issue tracker…
Improvements in ejabberd Business Edition
Customers of the
ejabberd Business Edition
, in addition to all those improvements and bugfixes, also get:
Pushy.me
-
Add support for the
Pushy.me
notification service for Mobile App
Android Push
-
Add support for the
new FCMv1 API
for Android Push
-
Improve errors reporting for wrong options in
mod_gcm
Apple Push
-
Update support for Apple Push API
-
Add support for p12 certificate in
mod_applepush
-
Add
tls_verify
option to
mod_applepush
-
Improve errors reporting for wrong options in
mod_applepush
Webpush
-
Properly initialize subject in Webpush
Push
-
Add new API commands
setup_push
,
get_push_setup
and
delete_push_setup
for managing push setup, with support for Apple Push, Android Push, Pushy.me and Webpush/Webhook
ChangeLog
This is a more detailed list of changes in this ejabberd release:
Core
-
econf
: Add ability to use additional custom errors when parsing options
-
ejabberd_logger
: Reloading configuration will update logger settings
-
gen_mod
: Add support to specify a hook global, not vhost-specific
-
mod_configure
: Retract
Get User Password
command to update
XEP-0133
1.3.0
-
mod_conversejs
: Simplify support for
@HOST@
in
default_domain
option (
#4167
)
-
mod_mam
: Document that
XEP-0441
is implemented as well
-
mod_mam
: Update support for
XEP-0425
version 0.3.0, keep supporting 0.2.1 (
#4193
)
-
mod_matrix_gw
: Fix support for
@HOST@
in
matrix_domain
option (
#4167
)
-
mod_muc_log
: Hide join/leave lines, add method to show them
-
mod_muc_log
: Support
allowpm
introduced in 2bd61ab
-
mod_muc_room
: Use ejabberd hooks instead of function calls to
mod_muc_log
(
#4191
)
-
mod_private
: Cope with bookmark decoding errors
-
mod_vcard_xupdate
: Send hash after avatar get set for first time
-
prosody2ejabberd
: Handle the
approved
attribute. As feature isn’t implemented, discard it (
#4188
)
SQL
-
update_sql_schema
: Enable this option by default
-
CI: Don’t load database schema files for mysql and pgsql
-
Support Unix Domain Socket with updated p1_pgsql and p1_mysql (
#3716
)
-
Fix handling of
mqtt_pub
table definition from
mysql.sql
and fix
should_update_schema/1
in
ejabberd_sql_schema.erl
-
Don’t start sql connection pools for unknown hosts
-
Add
update_primary_key
command to sql schema updater
-
Fix crash running
export2sql
when MAM enabled but MUC disabled
-
Improve detection of types in odbc
Commands API
-
New ban commands use private storage to keep ban information (
#4201
)
-
join_cluster_here
: New command to join a remote node into our local cluster
-
Don’t name integer and string results in API examples (
#4198
)
-
get_user_subscriptions
: Fix validation of user field in that command
-
mod_admin_extra
: Handle case when
mod_private
is not enabled (
#4201
)
-
mod_muc_admin
: Improve validation of arguments in several commands
Compile
-
ejabberdctl
: Comment ERTS_VSN variable when not used (
#4194
)
-
ejabberdctl
: Fix iexlive after
make prod
when using Elixir
-
ejabberdctl
: If
INET_DIST_INTERFACE
is IPv6, set required option (
#4189
)
-
ejabberdctl
: Make native dynamic node names work when using fully qualified domain names
-
rebar.config.script
: Support relaxed dependency version (
#4192
)
-
rebar.config
: Update deps version to rebar3’s relaxed versioning
-
rebar.lock
: Track file, now that rebar3 uses loose dependency versioning
-
configure.ac
: When using rebar3, unlock dependencies that are disabled (
#4212
)
-
configure.ac
: When using rebar3 with old Erlang, unlock some dependencies (
#4213
)
-
mix:exs
: Move
xmpp
from
included_applications
to
applications
Dependencies
-
Base64url: Use only when using rebar2 and Erlang lower than 24
-
Idna: Bump from 6.0.0 to 6.1.1
-
Jiffy: Use Json module when Erlang/OTP 27, jiffy with older ones
-
Jose: Update to the new 1.11.10 for Erlang/OTP higher than 23
-
Luerl: Update to 1.2.0 when OTP same or higher than 20, simplifies commit a09f222
-
P1_acme: Update to support Jose 1.11.10 and Ipv6 support (
#4170
)
-
P1_acme: Update to use Erlang’s json library instead of jiffy when OTP 27
-
Port_compiler: Update to 1.15.0 that supports Erlang/OTP 27.0
Development Help
-
.gitignore
: Ignore ctags/etags files
-
make dialyzer
: Add support to run Dialyzer with Mix
-
make format|indent
: New targets to format and indent source code
-
make relive
: Add Sync tool with Rebar3, ExSync with Mix
-
hook_deps
: Use precise name: hooks are added and later deleted, not removed
-
hook_deps
: Fix to handle FileNo as tuple
{FileNumber, CharacterPosition}
-
Add support to test also EUnit suite
-
Fix
code:lib_dir
call to work with Erlang/OTP 27.0-rc2
-
Set process flags when Erlang/OTP 27 to help debugging
-
Test retractions in mam_tests
Documentation
-
Add some XEPs support that was forgotten
-
Fix documentation links to new URLs generated by MkDocs
-
Remove
...
in example configuration: it is assumed and reduces verbosity
-
Support for version note in modules too
-
Mark toplevel options, commands and modules that changed in latest version
-
Now modules themselves can have version annotations in
note
Installers and Container
-
make-binaries: Bump Erlang/OTP to 26.2.5 and Elixir 1.16.3
-
make-binaries: Bump OpenSSL to 3.3.1
-
make-binaries: Bump Linux-PAM to 1.6.1
-
make-binaries: Bump Expat to 2.6.2
-
make-binaries: Revert temporarily an OTP commit that breaks MSSQL (
#4178
)
-
CONTAINER.md: Invalid
CTL_ON_CREATE
usage in docker-compose example
WebAdmin
-
ejabberd_ctl: Improve parsing of commas in arguments
-
ejabberd_ctl: Fix output of UTF-8-encoded binaries
-
WebAdmin: Remove webadmin_view for now, as commands allow more fine-grained permissions
-
WebAdmin: Unauthorized response: include some text to direct to the logs
-
WebAdmin: Improve home page
-
WebAdmin: Sort alphabetically the menu items, except the most used ones
-
WebAdmin: New login box in the left menu bar
-
WebAdmin: Add make_command functions to produce HTML command element
-
Document ‘any’ argument and result type, useful for internal commands
-
Commands with ‘internal’ tag: don’t list and block execution by frontends
-
WebAdmin: Move content to commands; new pages; hook changes; new commands
Full Changelog
https://github.com/processone/ejabberd/compare/24.02…24.06
ejabberd 24.06 download & feedback
As usual, the release is tagged in the Git source code repository on
GitHub
.
The source package and installers are available in
ejabberd Downloads
page. To check the
*.asc
signature files, see
How to verify ProcessOne downloads integrity
.
For convenience, there are alternative download locations like the
ejabberd DEB/RPM Packages Repository
and the
GitHub Release / Tags
.
The
ecs
container image is available in
docker.io/ejabberd/ecs
and
ghcr.io/processone/ecs
. The alternative
ejabberd
container image is available in
ghcr.io/processone/ejabberd
.
If you consider that you’ve found a bug, please search or fill a bug report on
GitHub Issues
.
The post
ejabberd 24.06
first appeared on
ProcessOne
.

chevron_right

 Privacy is Priceless, but Signal is Expensive
Privacy is Priceless, but Signal is Expensive