We often talk about the suitability of the BEAM VM for the Healthcare industry. Afterall, when it comes to Healthcare, downtime can literally be deadly, and no technology is better equipped to deliver high availability and minimal downtime than the BEAM. At Code BEAM V 2020, Bryan Hunter, an Enterprise fellow at one of the biggest Healthcare providers in the world joined us to share how the BEAM empowered their healthcare systems, meaning they were prepared for surges in demand caused by the COVID-19 pandemic. You can watch his talk below, or read the transcript which follows.
If you want to be the first to see the amazing stories shared at our conferences you can join us at ElixirConf EU will be held on 7-8 April in London and online, Code BEAM Europe , 19-20 May in Stockholm and Online or Code BEAM America , 3-4 November, in Mountain View or online. We hope to see you soon.
Intro
I am an Enterprise Fellow at HCA Healthcare . HCA is big. There are 186 hospitals and 2,000 surgery centers, freestanding emergency rooms, and clinics. So, a lot of people truly depend on us doing things right.
In 2017, we were given an R&D challenge. If we had all of the data, which we do in the group I’m in and ErlangVM, what good could we do? Could we improve patient outcomes? Could we help the caregivers, the doctors, and nurses in the field? Could we give our hospitals a better footing in case there were disasters or pandemics? Luck favors the prepared, as the saying goes. So we were in a pretty good spot to help out as things got nasty.
Project Waterpark
We also wanted to tackle these things in this research that we’re doing. We had these goals of adding Dev Joy, Biz Joy, and Ops Joy. So, for Devs, we could help them be more productive. We could make it an easier place to do more important work. And for the business, if we could have faster delivery times and less risk to projects, that would make the business happy.
For operations, if we can just simplify the management of the systems, and if we could have things stand up and fall as units, and if we could be more fault-tolerant, that makes Ops happier. So, those were on our menu as we began the research.
We came up with this project that we called Waterpark. The name is sort of a funny name. But the idea of it is you get this thing, it’s big, and there’s lots of stuff flowing through it, and it’s fast, and we talk about all that joy. So, it’s fast and it’s fun. And instead of it being like a data lake as just some other place where data just goes and sits around or a data swamp, it’s more like a waterpark. A water park is much like the internet, it’s a series of tubes.
The waterpark is this thing that came out of all this research and development. It started being a product back in 2018. It started being built up as a product then. So, this service runs on a cluster across multiple data centers. It’s all in ErlangVM. We have data that comes into Waterpark, and we have data that goes out of Waterpark. We’re housed inside an Enterprise integration group. All the data passes through here. You can think of this as the switchboard operators that hook the cables here, and the data routes from place to place from this medical system to this medical system.
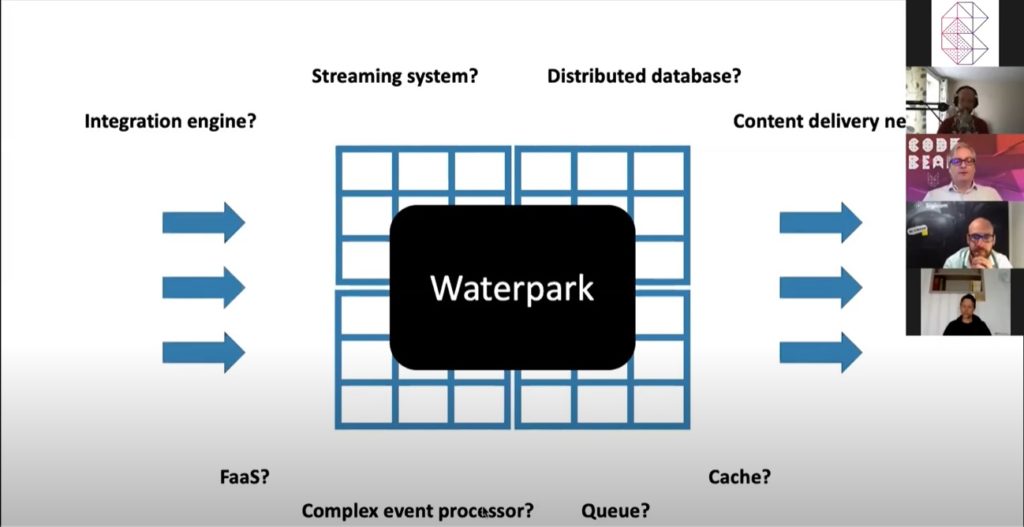
Waterpark plays a lot of bases. You could look at it as an integration engine or a streaming system, say like Kafka , where you could look at it as a distributed database like React or Casandra . It’s like a CDN. Data is gonna be close to where you need to read it, a cache, a queue, a complex event processor, or as a function of the service platform.
The reason it has all of these different identities is what we wanted to do is we needed little bits of each of those. So we implemented little bits of each of those. We had the minimal set of things that we needed to support our business use cases and we implemented them directly in ErlangVM and Elixir so that we wouldn’t take dependencies on Kafka.
We use Kafka, we write to Kafka, but we’re only doing that to push data to people that want to read their data from Kafka rather than, say, Rabbit . We use different queues and different caches and different things but we don’t depend on them ourselves. And so, if those things go down, it doesn’t make us go down.
Healthcare Data
A little bit about just healthcare data, just a little bit of the domain here. You can see that we’ve got a patient, caregiver. Those are things that people are familiar with. Then, you also have a lot of administration like admin at individual hospitals, and then the executives. The types of data that goes through these medical record systems, these EMRs, you’ll have information about admits discharges and transfers. So, someone comes to a hospital, admit, they’re moved to another room and they’re transferred. You have orders. Say you get an order to get X-rays done or observation results. Here are your results from this lab test that you took. As far as pharmacy, the pharmacy within in the hospital as far as the medications that are ordered and administered to the patients and scheduling and so forth. So, that gives you kind of a broad idea of the business bits that we’re talking about within this business of healthcare.
HL7
All that data, well, almost all that data, is around this three-letter thing called HL7. I had heard of HL7 but I had never seen it up until 2017 when I began this research. It suddenly became very, very important to me. So, here’s your first view of HL7 if you haven’t seen it.

I’ll make it slightly easier by giving a little bit of space in this thing. And so, here, I’ve broken it up where each one of the segments, I put some space between it, and I’ve highlighted the segment header, these three-letter things at the beginning. And so, this is HL7.
This is our first place where the ErlangVM pops in and is handy for us and Elixir and Erlang, so the bit syntax. We can crack into this thing with the bit syntax, and we do this. So this is happening all day long right now. There is some Erlang code, some Elixir code, that’s chunking through and matching off of millions and millions of messages off of this pattern match. It’s making sure that the first three bytes are the MSH, message header. Then, after that, this score thing, this is strange. You would look at this and you might think that this would be that oh, we’ve got a file and it’s pipe limited, and the fields are pipe limited. That’s not quite the truth.
So, what this fourth character does is tell us what the field delimiter is within this message. And then we have these four bytes of the coding characters. We have a thing that says within a field if it has some components, how are we gonna delimit those? Then, we have the tilde that’s gonna tell us…in that position, it tells us that this is what’s gonna delimit if we have repeating groups within a field. We have lists of data within a field. Then the ampersand there is there telling us about subcomponents. We also have the slash to tell us what the escape character is.
Then, notice this. Our field separator appears again here in this match. What we’re doing is we’re doing a declarative match saying that the fourth character had better darn well match this character. If it doesn’t, this is broken. So, since we have those things being equal here in this pattern match, only something that’s probably HL7 is gonna make it through this match. This will give you an idea. We could change that delimiter from pipe to at sign, and the messages would look something like that, which is kinda fun.
Back to our message we will discuss the a little bit more the structure. We won’t spend a whole lot of time here but I think it’s helpful to get an idea of the kind of data that’s passing through here. If we look at this MSH segment this is the notation that people use as they’re talking about paths within HL7 data. It’s MSH-3. And that field is the sending application, and you have the sending facility. So, we’re talking about data that’s being glued from one medical system into another one. And so, the sending facility is sending this HL7 out, and it’s sending it to a receiving application that’s maybe at a different facility, or maybe it’s within the same facility. Then we have our message date, and you can see this thing of the year, month, day, hour, minute. Sometimes you’ll see seconds. Sometimes you won’t see seconds. The granularity might be just to the minute. Sometimes you will see the UTC offset. Sometimes you don’t. So, it varies by the implementation that you’re doing with them by the actual product that’s emitting the HL7.

Then we go over and we have a message type. This tells us what kind of message this thing is and what all these segments down below are gonna tell us about this patient.
Here we have ADT, and that’s gonna be like we saw just a second ago, the admits discharges and the transfers. So, it’s gonna be one of those. This is the case of a patient that’s just arrived at a facility. And this is a message ID that’s unique within that sending application, you know. So, this is not a GUID. It could be a GUID, but it’s not in this case. That’s sorta unique as, sorta, the joke goes. Then we have an HL7 version. We will have this version define which version of HL7 spec we’re looking at here. So, different versions will have additional message types, have additional segment types. They will add additional fields to the end of a segment that existed in an earlier HL7 version, and so on.
And dealing with HL7 is critically important from the beginning when we started with Waterpark. I’d never used it, and all of a sudden, it was the most important thing in my life.
We started out building ways of dealing with HL7 in Elixir. And we needed this library, so we built it. I’m proud that HCA made this work available to the community. Raising all boats and caring for the community, that’s cool stuff.
Another thing that makes me happy about this is this is another good reason for healthcare companies to use Elixir. So, there’s a solid HL7 library here that’s being used day by day for critical things, and so they know they can count on us.
How do we crack in and use this library that we’re talking about here? And so, I got a message. We’re gonna store a message. We’re gonna parse this message, this HL7 text that’s on the screen here. The HL7 parser grabs it and then creates this structure off of it. We can pipe that message into the HL7 query and then say, “Get parts.” And so, here is an HL7 path. This is a common thing where your AL1 is pointing at a segment down there. The -3 tells you what field we limit, and then the .2 tells you what component is within that field. So, here we are, .1, first field, second field, third field, and then the second component within that, and then, boom, it’s the aspirin that we were pointing at with that.
Long-lived Digital Twins
Another bit that’s very important to us is we need to survive if we have process crashes. There’s this idea of long-lived digital twins that we use a lot. In Waterpark, we’re modeling the world. We’re modeling our world, and we’re not thinking about this as rows in a database or Erlang process per patient, not database row per patient. So, typically, in healthcare, a patient is represented as a block of data. It’s a snapshot on disc. It might be HL7. It might be JSON. It might be whatever. It’s just there, and systems read that patient data and they do some work on that value and then they flush it from their memory, and they move on. There’s no memory of the things they just were looking at. They’re just jumping, jump, jump through data, and there’s no, sort of, continuity idea.
In Waterpark, we model each patient that comes into the facilities as a long-running patient actor, a GenServer. So, a patient actor represents and is dedicated to an individual patient. These patient actors run from pre-admit to post-discharge. That may be for weeks that this Erlang process, this GenServer is up and running. It might be running for weeks. A patient actor is not limited to the data in the latest HL7 message that came to it. It’s gonna hold every HL7 message and event that led to that patient actor’s current state. So, that may be thousands of messages. And from there, you might be thinking about memory, memory usage.

We think about memory usage too. And we’re memory-efficient. We’re doing a lot, and we end up with low memory usage on our boxes. So, we store the messages compressed, and HL7 compresses them well. Our GenServers, hibernate when there’s no activity. And we have eviction policies. So, if there’s an outlier that has just some sort of extreme thing, we evict the outlier so that it doesn’t ruin the fun for everyone else.
The long shift
Here’s a side view of the long shift at hospitals. So, nurses, often work these 12-hour shifts. And this is to provide continuity of care so that there are fewer handoffs during the day. So, two instead of three. This quote from the Joint Commission is kinda scary. It’s 80% of serious medical errors involve miscommunication during handoffs during the transitioning of care. And so, that 12-hour thing is to help address that. And we look at the patient actors as an extension of this long shift idea so we can provide continuity of care to our systems. Instead of just having, you know, that one moment in time view of the record in front of us, we have this long view of what’s happening with the patient. Full visit awareness enables real-time notifications and alerts that are based on weeks of complex things happening. You know, all of the chain of things that have happened for that patient.

We think about memory usage too. And we’re memory-efficient. We’re doing a lot, and we end up with low memory usage on our boxes. So, we store the messages compressed, and HL7 compresses them well. Our GenServers, hibernate when there’s no activity. And we have eviction policies. So, if there’s an outlier that has just some sort of extreme thing, we evict the outlier so that it doesn’t ruin the fun for everyone else.
The long shift
Here’s a side view of the long shift at hospitals. So, nurses, often work these 12-hour shifts. And this is to provide continuity of care so that there are fewer handoffs during the day. So, two instead of three. This quote from the Joint Commission is kinda scary. It’s 80% of serious medical errors involve miscommunication during handoffs during the transitioning of care. And so, that 12-hour thing is to help address that. And we look at the patient actors as an extension of this long shift idea so we can provide continuity of care to our systems. Instead of just having, you know, that one moment in time view of the record in front of us, we have this long view of what’s happening with the patient. Full visit awareness enables real-time notifications and alerts that are based on weeks of complex things happening. You know, all of the chain of things that have happened for that patient.

So, here is a little bit of a diagram that shows a little bit of what we’re talking about to visualize it, so, a patient 1001, 1002 at a facility. So, we receive patients. Then it says, “HL7 messages and create a patient actor per patient to process the messages.” So, here, the message comes out from this patient, and over on Waterpark, we spin up a patient actor. And that patient actor follows that message. And we then update our projections to say, “Oh, we have an admission.” We have another one that comes through on this message and we realize oh, okay, this was an order, administration of aspirin for the patient. Now that patient comes in. It doesn’t exist yet. So, it’s spun up, and this patient is admitted, and we have this other one here. And we see this whole transcript being built up over these messages that maybe came in over hours. Both these actors are just hanging out there waiting for the next thing.

Continuous Availability
You put all this data out there, and you have all these actors spun up. Then, you want to take a big 12-hour weekend to scrub your servers down or something, you know, to do maintenance. Well, that’s not gonna work. We have an idea how to fix that in Waterpark. We have to be continuously available. This is not just high availability. We just can’t ever go down. That means that we can have no unplanned outages. We have to be fault-tolerant. We have to, you know, be fault-tolerant so we don’t fail by mistake. If we fail, we need it to be limited. We also need to not have any planned outages. We can’t take downtimes for patching or releases.
To get there, we have to follow this pretty closely, this idea of no masters, no single point of failure. So, we have a task router node and three worker nodes. There’s a single point of failure there. If this thing goes down, we’re not getting any work done. We have probably a more common…or just as common, we have three worker nodes, and they’re all pointing at some shared storage where this is a database where if it’s shared storage in a rack in some closet. We think about this one not just at the software level but also at the hardware and network and infrastructure level as well, these single points of failure.
So, here have roles in series, web, business logic, and database. And so, this is called the n-tier architecture, and you could also call it the worst high-availability plan ever, to have these things stacked up with these different roles. And let’s see why. So, what’s the problem with that? So, we have a component, and it has three 9s of availability. That gives us about 8.8 hours of downtime a year we can expect for this thing. And if we chain three of these components together with one way versus another, we get quite different results. And so, if we put them in series, if any one of these things fails, we’re stuck. If any of the components fail in a series, we don’t perform our operation. On the right, we have three things that are running in parallel, they’re all peers, and if one of them fails, you can just move on to one of the others and have it do the work. So, work is still being processed. And so, this same component of three 9s of reliability, that 8.8 hours, in series, we get 99.7% uptime or 26.3 hours per year downtime. And over here, just by having these three components, we get this nice…the math gives us this nice thing of nine 9s. It’s 32 milliseconds per year. And so, that idea is really attractive to us of having things be a series of peers that don’t depend on masters.

And so, we work hard to avoid single points of failure, and we work hard. So, what’s better than three? Well, how about eight. And so, and what’s better than eight? How about if we put the eight that are there and we split them up so that the environment around the four on the left and the environment around the one on the right is broken up into entirely different availability zones? So, if the power fails at the building, the generators, everything goes wrong, the four on the left go away, the four on the right keep on churning. If the network completely fails, so we have completely separate networks, we can use availability zones. That gives you, then, another way of avoiding that single point of failure.
To extend this we have that at Florida, and we also have that at Tennessee, and we have that at Texas, and we have that at Utah. And so, if any of these fail we could lose not just a server and not affect availability, read availability, or we wouldn’t affect write availability if we lost a server either. We wouldn’t lose read availability even if we lost three of our four data centers. And for any message in the entire system, we would be able to read it if there was one data center available and reachable.
Let’s look at our model here quickly before we move on to the other bits. We have Florida here, and we have a patient 1001 that’s running on Florida A-2. We are also gonna have a read replica, a follower, a process pair of that process. So, read-writes only happen on the one that’s on Florida A-2 but reads could happen over here on this one at Florida E-2. And we’re also gonna have a read replica at Tennesse and Texas and Utah. And so, how do you manage where all of those things live? You have to think about, like, a global registry. You know, how does this even work? And so, we don’t do that. And so, how do we manage it all? Well, we user server hashrings.
If you’ve worked at Basho or if you’ve ever used Riak , you might have some guesses about what we’re about to see here. I didn’t disappoint. We have a picture of a ring, so we should get oohs and ahs and love from that crowd. So, we’re using the hashring. We have hr=HashRing. Let’s move up. Let’s add some nodes.
We got our eight nodes here. We’re gonna add them. We have this hashring. Then we can say, “HashRing.key_to_node,” and we give it actor key 1001, and so, we get this guy. And actor key 1001 will always go to S7. It doesn’t matter, you know, what the weather is like. It doesn’t matter what the world’s like. It’s always gonna go to S7 unless the topology itself changes, or unless the membership of that hashring changes.

Topologies
I mentioned Topology but let’s look at what I specifically mean in Waterpark’s context of this. We have our Tennessee, Texas, Utah, and Florida. And so, if we get DCs, we’ll see TN, TX, UT, and Florida. If we ask topology to “get_dc_ hash_ring” of Tennessee, we get its hashring. So basically the Topology sits around this map where it’s keyed off of the data center, and each of the keys points then to the hashring of the servers at that data center. If we say, “Topology. get_current,” we gonna get our entire current topology. This is a simplified version of actually what’s really in Waterpark, but this gives you the idea.
That’s not simple at all, but what we’re looking at in the code, we have multiple versions in Topology, but that’s getting way in the weeds. And so, “Topology.get_current,” and so, we get this, we see the whole map. “Topology.get_actor_server,” and we patch in a key that has an ID and a facility on it. It says that’s at Tennessee B-2. So, that facility mapped us, said, “Okay, that thing is gonna be existing at Tennessee, and this key is gonna map that particular node at Tennessee.”

If we can just have all of our servers, all of our nodes sharing…having strong consensus on Topology, then we don’t have to have any sort of consensus around, like, what a global registry might give us. We use math for the part that’s hard and expensive of synchronizing when having a global registry. We just get out of that problem entirely. We don’t have that problem. We instead say, “Get us just the address of the server. That’s all we need.” We can do that off of math. The only thing we have to have is we have to have a mechanism of strong consensus, say Raft or Axos, basically to make sure that all those nodes agree on what the Topology looks like. Once they do, everyone has the same map, and they will get to the right place, given a key.
So, let’s talk about process pairs. Tandem computing, tandem computers back in, let’s see, 1985, this paper, “Why Do Computers Stop and What Can Be Done About It?”And so, Tandem was known for these computers that had…they had two computers, and they were constantly replicating their memory back and forth so that if the computer was shut down, another computer would keep on going with whatever the state was that that other computer had.
This technique was definitely in the air and the minds of Joe and Robert and gang and Mike in the early days of Erlang. Here’s Joe talking about this problem. And so, it’s saying if the machine crashes, you want another machine to be able to detect it, pick it up, and carry on. That user shouldn’t even notice the failure.

So, here’s what happens though. When people come into the ErlangVM, you’re new to the ErlangVM, you’re programming along, and you’re like, “Okay, I know about supervisors. This is the way to have highly-available systems. I’m gonna have a supervisor that starts a child. It’s a process that has no data now. I’m gonna get some data, process get some data, and then get some more data,” and then your process crashes. The supervisor restarts the process, and then you have a process with no data. This is the big head-scratcher because there’s this intuitive gap between what OTP and supervision give you versus what people expect. A lot of people get stumped by this, and they think that the supervisor is gonna somehow retrieve and bring their GenServer back to the state it was right before the crash. And, of course, that’s not the way it is, and you have to roll your own there. You have to figure out how your process pairs are gonna work.
This is a reply from Joe I just absolutely love from Pipermail 2011 where he’s explaining this situation to someone that had asked that same question. Rather than reading here, we’ll just walk through the animations of it. I think you are getting confused between OTP, supervisors, etc., and the general notion of takeover. Let’s start with how we do error recovery. Imagine two linked processes, A and B, on separate machines. A is the master process. B is the process that takes over if A fails. A sends a stream of state update messages, S1, 2, 3, or S, yeah, 1, 2, 3 to B. And I hope these animations are coming through over Zoom because I spent a lot of time. And so, all right, cool. Thanks, Mike.
The state messages contain enough information for B to do whatever A was doing should A fail. And so, if A fails, B will receive an EXIT signal. If B does receive an EXIT signal, it knows A has failed. So, it carries on doing whatever A was doing using the information it last received in the state update message. If we use Joe’s language here, I just love it, “That’s it, all about it, nothing to do with supervisors, etc.” I think that this one post probably opened a lot of people’s eyes. This thing keeps on being found by people. I had never seen it in a talk, and so I wanted to include it here as a salute. This idea is important to us, the process pairs. We have four pairs instead of one though.
So, location transparency is another Pipermail thing from Joe. He’s saying however it works in the distributor case is how it should work locally. This is a super powerful idea on ErlangVM. I think it doesn’t get taken as seriously sometimes as I think it should. This idea of the location transparency of things behaving the same other than the latency of physics is one of the main reasons, key reasons, that Waterpark is built on the Beam. But, the batteries aren’t included. Everything is not there for you. So, you’re gonna have to build some kit whenever you want to use Distributor Erlang. I think if they were a little bit more built-in libraries people would rely on Distributor Erlang a lot more for things like process pairs rather than everyone falling back and saying, “Okay. We have to put our data in Postgres.”
For example, Waterpark doesn’t use a database. Waterpark is a database. It’s a series of peers, and they all spread the data across. There is no writing to an external database.
In Waterpark, each node is a peer. Any node can receive a message. No one on the outside knows or cares about the cluster. They don’t know about hashrings, registries, etc. Each node has a mailroom. So, you could call this whatever, but this is the abstraction that we have that sits up on top of things around the distribution bits. The mailroom knows about the Topology. It knows how to use it to deliver things. Inbound messages are routed through the mailroom to the appropriate patient actor. So, someone on the outside just sent that message over to Florida B2. They had no idea really where the actor was that needed to deal with that thing.
If the patient is remote, the mailroom routes the message to the remote node’s mailroom. So, it goes zippity zip over there. And if in-flight, if that message was going across the world, the Topology changed.

If there was a node that was being bounced for some reason or something and the Topology changes in-flight, no big deal. No server retry happens. This mailroom just helpfully re-routes it to the correct mailroom. It goes over to that mailroom. The local mailroom then delivers the message to the correct patient actor at that point. And so, we go over here, and we have our admit on this patient.
A super-powerful idea of a mailroom or something along with this abstraction on top because it provides a beautiful seam here for testing. You have your unit test, your property-based test. It’s a place where you can bundle data. If you know a group of data’s about to be routed to one server, you might get some efficiencies.
There are projects out there, Discord has one, where they bundle messages so that they can send as a bundle to a given target. We’re not using that. We have our bits. It’s also a perfect place to compress. Right before the data goes over the network, and you know that you’re gonna get this orders of magnitude slowness as you go off of your machine across the network, a pretty smart thing is to compress that data, and so we do that.
Every packet that goes out is being compressed, and it’s being compressed all in this one place without anyone having to know or care about this. It’s a good way of hiding icky bits like RPC and the errors and so on from Erlang’s goo leaking out. We can hide all that and provide this interface where we could then pick up and easily replace the distribution. If we say “Okay. We don’t want to use Distributor Erlang for this. Maybe what we want to do is we want to have Morris Code through flashlights out the window to your neighbor’s window.” We could have that implementation backing the mailroom, and everything would happen, and it would just be really slow.
Inside of our code, we have no references to Erlang or Elixir’s distributed bits. They’re all contained within this one workplace. The idea of stating invariants, I think, is really powerful. It might be mind-numbing to listen to them. This wave of facts about a system that you write down is really useful I believe. It will give you a different view of Waterpark. Every patient actor has a key. The facility of a patient is part of the patient actor’s key. Topology uses the facility portion of the key to determining the data center of the patient actor. Topology deterministically maps a patient actor to one node in the cluster by its key.
Every patient actor is registered by key on its node’s local registry. This is using the Exilir registry. Every patient actor is supervised. Commands are delivered to a patient actor via the mailroom. If the patient actor is not running when a command is delivered, it will be started. If Topology has changed and the patient actor’s key no longer maps to its current node, it will migrate to the current node. So, it will send a message over to where it should be. And that node will be happy to spin up that process. The data will be migrated, and this process will terminate. All this migration is automatically just done as just a platform.
Every patient actor has one read-only follower process at each data center. A patient actor processes commands and emits events. Before a patient actor commits an event to its event log, two of its four read-only followers must acknowledge receipt of the event. So it’s not that we only care about two. We just immediately return success at the point that it’s made it to enough of them. And then the others will reach it soon enough. When a patient actor starts…and so, generally that’s gonna be writing probably to a reader. The fastest ones that are gonna reply will be a reader at the local DC, and then, write a reader at the DC that is geographically nearest where we’re at. And then the others will just lag.
When a patient actor starts it will ask via mailroom if its four read-only followers have stated. So, I’ve just appeared in the world. I’m gonna reach out and say, “Hey, do I have any readers out there and do you have any state?” And if they do, that means we crashed. We’re recovering from a crash. We’re gonna take the state of the best reader. Each patient actor’s state contains its key, an event store, and a map for event handler plugins to store projections. This is the part where all of the good bits tie in. This is where we’re doing the clinical work that we’re doing on these ideas of the event handler plugins.
Event Handler Plugins
We have an infinite stream of data coming through. We have this idea of the patient actor here with its key projections and events store and this collection of event handler plugins that have been registered. The event handlers will need these specs. They’re gonna handle and they’re gonna be given the existing projections, the key of the patient actor, and an HL7 message to deal with, and then the events store that contains all of the events that have previously happened on that patient.
COVID-19 Long-Term Care Facility Alerts
If we take the case of the COVID-19 long-term care facility alerts everyone knows that the elderly are a high-risk bunch with this disease. And communities of elderly at nursing homes and long-term facilities, really have been hit hard. You’ve got gathered together. There are a lot of contacts. It’s a nasty series of things that came together here. Ther is a project early in the pandemic that took Waterpark from being this cool tech project that was useful and neat to being essential was the long-term care facility alerts.
The idea of the plugins here is event handlers. The plugins are these modules, and they implement a behavior, and they’re stateless, and they infer meaning from the messages. They learn things and then they write them back into the projections. So, you have this chain of these handlers that are coming together. Oftentimes, the handlers are filled with conflicts of events rules, that maybe you’re dealing with messages that happen days apart. In the alerting plugins, we often follow this model, say, in Atul Gawande’s “Checklist Manifesto” of basically having the projections for that particular event handler holding a checklist. It goes through the checklist and each one of these checks is answered by an English-phrased function. It’s a pure function. The given data returns yes or no. This is a perfect place here around the handlers to put property-based tests, and we do. We have lots and lots of property-based testing in Waterpark. And a lot of them are focused around this incredibly complex area of these event handlers.
Let’s look at what happens in the long-term care facility alert handler. We have these three questions. This is a simplified version of the thing. But we want to see the status for every patient out there, they maybe are or maybe they’re not a long-term care transfer. Maybe they were transferred from a nursing home or not. And maybe along with their stay, a lab result comes back for a COVID test and they’re positive. So, this might happen to any patient. But if it’s a combination of them being long-term care patients and COVID-positive, we want to send an alert. We want to send an alert to the case manager at the hospital where that patient is to let them know what has just happened. In this way, the case manager can contact the nursing home and help them with extra testing and tracking, and so on. Otherwise, they’re just blind, and this whole problem, they might not even know what’s going on.

This is a powerful idea. And also, the third question on here, have we already sent the alert? So, we don’t want to keep on sending the same alert over and over or the same patients as additional messages come in. We have this additional check here. Then hours later, the message comes in. We find COVID-positive, and they haven’t already been alerted. So, we know we want to alert. We click over. The message goes out to the case manager, and then we mark and we say, “Has the patient been alerted?” And so, this alert won’t happen again as a result of that.
I also wanted to mention just a couple of things about this infinite stream of data coming through. As you’ve seen earlier by the keys in streaming systems, we could say this is session windowing. We’re windowing based on the patient that we’re dealing with. And it’s bounded because we’re not holding infinite data around the patient. We’re gonna hold the data up to whatever the windows are of those rules we were talking about earlier around eviction. And then we do exactly-once processing.
Across the cluster, if an HL7 message comes in, it’s going to be targeted to one exact patient. There’s only one patient…out of the millions of processes that are running on the cluster, there’s only one process that can handle an HL7 message. And that is the GenServer for that human, that digital twin. And it’s gonna go through there. And that process, when it catches that message, it’s going to compare that message’s hash against its event log and say, “Do I have this hash in my event log? Oh, I do. I’m not gonna process this thing again.” And so, you have exactly-once processing across this distributed cluster, which is pretty powerful. Bloom filters come in a lot. Probabilistic data structures come in a lot around indexing of data to make things quick, aggregating, and so on. As you can see, this is a really smart thing to be able to have these data structures in. And you can do powerful things, including full-text indexing on everything. So, you can Google on whatever your domain is using bloom filters around the [inaudible 00:40:41] talking about.
Deployments
Deployments. I will blaze through this. I know that we’re at the end of the day too, but that’s not the most awful thing, but we have three modes of deployment, releases with the distillery, hot code loading, and dark launches. So, our releases are kinda typical, you know, this is just Erlang releases going out through distillery. Easy at a time it’s being balanced and brought up. Now, this creates a lot of churn on the network because each one of these boxes that is still up, sees its buddies at the other AC fall down, it’s gotta handle the load of those and it’s gotta handle the write operations. There’s a fair amount of data going through. This is just a little process. We do it over the kind of a long window. We do a lot of releases. So, over this year, we’ve done over a hundred deployments.
Hot code releases work more like this where we’d say patch, and we have the data of our patch, and then say deploy, and oop, everything gets hit immediately at the same time. Our code is deployed across the cluster in two seconds. We have our okays from everywhere, and that’s nice. We’re not using upgrade releases. This is not an OTP release that we’re doing here. We’re using the primitives that are underneath or just in ErlangVM here. We’re pushing modules, and we’ve added some extra kit around pushing plugins. When we push a module, we’re just pushing the binary across and it’s good. When we’re pushing plugins, we’re grabbing a file, and we’re doing also some validation on it that it needs a contract before it gets hooked into the patient actor pipeline. Then we’re done reloading the thing. The new file is pushed out there, compiled. So, it will be there whenever…if it reboots, then it will reload.
Then dark launches are following the same idea, except for what we’re doing here is we push a normal release out. If we have some features that it would be nasty if it was working at half the cluster. So, we push it out as a normal release with the feature flag turned off, and then we push out through config. Very similar, we’re pushing out a new runtime EXS, and then we’re pushing out the environment.
All of this would not be possible to do this system. So, if we had attempted to do what we were doing in CSharp, it wouldn’t have worked. If we had attempted it in Java, it wouldn’t have worked. We wouldn’t have gotten the results that we’re getting out of the system if it had been on any other platform. So, I just truly love the Beam.

I’m so thankful for the community, for all the people that have put time into building ErlangVM, the folks at Ericsson, Joe and Robert and Mike, and then Jose on the side…all the folks on the Elixir side that have made it such a productive and fun place to work. There are things I’m doing now because I’m at Elixir, one, is I’m getting big companies like HCA to embrace this language. More and more projects are spinning up in this language than I would have if it had been just on Erlang, even though the reason that it’s sticking is because of the ErlangVM. That combination is so powerful, and it makes me so happy, and it just fills me with the feels.
I was thinking about this earlier. If I’m old and on my deathbed and I’m looking back, and I’m proud of the work that I’ve done, and I know that it’s done good things, and it’s done good things for people, it’s gonna be this community that I owe that to. It’s all the work that you all have done.
Q&A
Bryan Hunter: Thank you. We blew probably past the questions. I don’t know if there are four minutes left or if I’m six minutes over. So, I’m not sure of the timing.
Dave: The other question is how long and how many people have worked on Project Waterpark’s system? And it sounds mature.
Bryan Hunter: It was an awfully small team. But, of course, you know, you look at how WhatsApp was released and, you know. the small number of engineers there. We’re doing a much, sort of, different deal. The initial R&D was pretty much me fumbling around for the first year, 2017. This is the thing I’m so thankful to HCA that they knew they had this platform that had a lot of promise. There was half a year of just free-form research and development of doing proof of concepts to see could we make this part of healthcare better? Could we make this better? And often, those proofs were so compelling that the thing got picked up as a project. So, then we started adding developers that at this point, today, we have four core members or five core members of the team that is doing day-to-day development. Other people have worked on the platform, but we have five people that are working on it. We have other people that are analysts. We have ops people, and we have all of that, but the code being written day-to-day is by the merry band. Now, we are probably going to be hiring. So, if anyone is fascinated by this and would like to come and work with us on Waterpark, that would be a treat to hear from you.
The post How HCA Healthcare used the BEAM to fight COVID – Code BEAM V Talk review appeared first on Erlang Solutions .

chevron_right